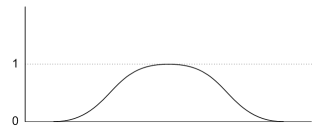
Factoren, combinatiesIn Generalisaties, menselijkWaar dit bij cultuurneutrale zaken als onderwijs al een probleem vormt, is dat bij cultuur-gekleurde zaken nog veel meer het geval. Gelukkig zijn veel hogere sociologische begrippen afhankelijk van meerdere sociologische parameters. Waarvoor de eigenaardige situatie geldt dat als die parameters onafhankelijk zijn, ze leiden tot een willekeurige verdeling, maar die was al willekeurig en willekeuriger dan willekeurig bestaat niet. Maar als die parameters niet willekeurig zijn, maken ze de verdeling scherper. Wat hier aangetoond gaat worden. Als basisvorm van onze vaag-begrensde eigenschap kiezen we een verdeling die enigszins op de Gaussiaanse lijkt, zie onder - dat kan het aantal mensen zijn dat een bepaalde eigenschap heeft, bijvoorbeeld lengte - met horizontaal de lengte en verticaal het aantal mensen met die lengte - voor het gemak van de berekeningen hebben we de maximale hoogte van de grafiek 1 gemaakt (in wiskundige termen: genormeerd), waarbij 1 bijvoorbeeld voor 1000 mensen staat:
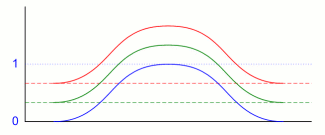
De combinatie van meerdere eigenschappen versimpelen we tot het geval dat de verdelingen ervan (ongeveer) hetzelfde uitzien - in onderstaande figuur hebben we er drie genomen, ieder met een eigen kleur. Omdat we ze in dezelfde grafiek hebben gezet, en toch niet over elkaar heen willen laten vallen, is de horizontale as voor iedere van de verdelingen wat verschoven, zodat ook de nulpunten telkens wat hoger liggen (lees deze en volgende grafieken van beneden naar boven).
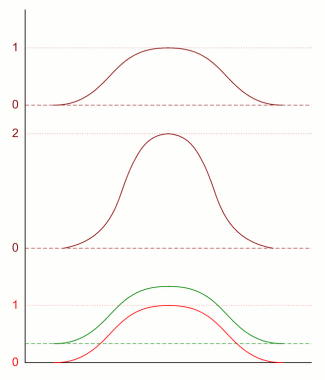
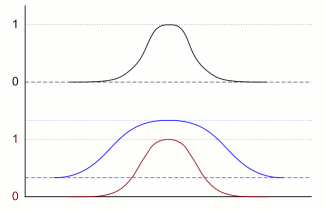
Nu gaan we deze verdelingen combineren. Daarvoor zijn twee principiëlere mogelijkheden: de eigenschappen die we combineren hebben niets met elkaar te maken, of de eigenschappen zijn afhankelijk van elkaar. Het eerste is bijvoorbeeld het geval bij lengte en muzikaliteit - er is nog nooit gebleken dat iemands muzikale talent van zijn lengte afhangt. Een voorbeeld van het tweede geval is lengte en gewicht - iemand van twee meter lang is meestal ook zwaarder dan iemand van anderhalve meter. Ook als je eigenschappen gaat combineren, kan je dat op een afhankelijke en een onafhankelijke manier doen. Als je iemand zoekt die of lang of muzikaal is, zeg je dat die twee onafhankelijk van elkaar zijn. Als je iemand zoekt die én lang én muzikaal is, maak je de twee eigenschappen afhankelijk van elkaar. Het combineren van onafhankelijke eigenschappen wordt wiskundig voorgesteld door het optellen van kansen en verdelingen: als de kans dat iemand erg muzikaal is 10 procent bedraagt, en dat hij erg lang is ook 10 procent, en je zoekt iemand die één van beide is, is je totale kans 20 procent. Als je daarentegen iemand zoekt die alletwee is, dan moet je met elkaar vermenigvuldigen, en de uiteindelijke kans is dan 1 procent (10 procent van 10 procent is een tiende van 10 procent). Wat betekent dat nu voor de verdelingen? We beginnen met het geval van onafhankelijke eigenschappen, en twee verdelingen, blauw en groen in de onderstaande figuur. Die tellen we bij elkaar op zodat je de bruine verdeling krijgt (dit doen voor een paar punten geeft al voldoende informatie om de trend te zien). Maar die bruine somgrafiek kan je niet vergelijken met de eerste twee, want die bruine is twee keer zo hoog. Je moet deze dus door twee delen - het hoeft geen verassing te zijn dat je dan precies dezelfde verdeling krijgt als de blauwe en de groene. Optellen verandert dus niets aan de vorm van verdelingen, als de oorspronkelijke tweede eenzelfde vorm hadden.
Het is duidelijk dat dit precies hetzelfde geldt als je er een derde verdeling bijneemt - dus dat laten we verder achterwege. Nu het geval van afhankelijke eigenschappen. Weer doen we dit met de eerder gebruikte blauwe en groene verdeling. Maar nu moet je vermenigvuldigen. De top van de grafiek blijft nu even hoog. Maar lage gedeelten worden extra laag - weer het geval van een tiende maal een tiende is een honderdste. De bruine grafiek ziet er duidelijk anders uit dan de originele. De bruine grafiek is een stuk smaller - het is een scherpere verdeling dan de rode of groene:
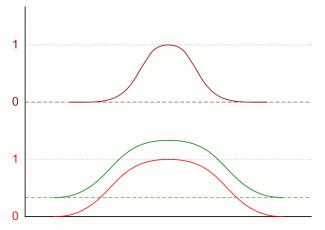
Oftewel: voor de combinatie van eigenschappen is het veel duidelijker wie wel of niet aan de combinatie voldoet dan voor de twee originele verdelingen. Ook geheel volgens ons praktijkvoorbeeld: als je de groep van muzikale én lange mensen zoekt, krijg je ook een selectere groep. Een trend die zich duidelijk voortzet als je een derde verdeling erbij neemt:
Vergeleken met de oorspronkelijke blauwe verdeling is het product van drie van die verdelingen, de zwarte, veel nauwer en veel beter gedefinieerd qua begrenzing. Het archetypische voorbeeld van de toepassing hiervan op sociologische gebied is natuurlijk het begrip "de Nederlander", ook wel geformuleerd als "dé Nederlander". Met dat laatste denkt men een onderscheid te maken met "de Nederlander", maar dat is natuurlijk onjuist. De enig mogelijke verdere uitwerking van "dé Nederlander" is "de gemiddelde Nederlander" en "de gemiddelde Nederlander" is precies hetzelfde als "de Nederlander". Wat men vermoedelijk bedoelt te zeggen is dus "De gemiddelde Nederlander bestaat niet", en dat is even juist als "Het gemiddelde kindertal van 2,3 bestaat niet". Klopt, als je het individuele geval gaat zoeken, maar klopt niet als je de gehele populatie bekijkt, of zelfs slechts honderd stuks, want dan zit je al heel dicht bij dat gemiddelde. Conclusie: wie zegt "Dé Nederlander bestaat niet" zegt "Er bestaan geen menselijke groepen" oftewel: "De hele wereld is één grote grijsgeelgroezelige monokleurige en monoculturele chaos". De situatie die voorafgaat aan ondergang ten gevolge van gebrek aan variatie en diversiteit. De werkelijkheid is natuurlijk dat als je vijf in Nederland verblijvende Turkse immigranten (van welke generatie dan ook) zet naast vijf Nederlanders, alleen een blinde het onderscheid niet kan waarnemen. En dat dat ook geldt voor het overgrote deel der niet op een foto zichtbare eigenschappen, als je het "zien" wat ruimer uitlegt. Op de sociale onbelangrijk zijnde eigenschappen van "Hebbende ook twee armen, twee benen en een hoofd" en soortgelijke na. Conclusie: culturele verschillen zijn essentieel voor een gezonde menselijke populatie. En zijn ook een essentieel hulpmiddel bij het bepalen van welke sociale en culturele eigenschappen belangrijk zijn en deel moeten uitmaken van een wetenschappelijke sociologie. Want leert de natuurkunde: de betrouwbaarste waarnemingen en metingen zijn die aan verschillen. Hiermee is wel redelijkerwijs vastgesteld dat het basisconcept van een wetenschappelijke aanpak: je kan over generalisaties of groepen praten, ook geldt voor de menswetenschappen. Als eerstvolgende een demonstratie vanuit de natuurkunde van wat je met deze aanpak kan bereiken Naar Psychosociohistorie, inleiding
|